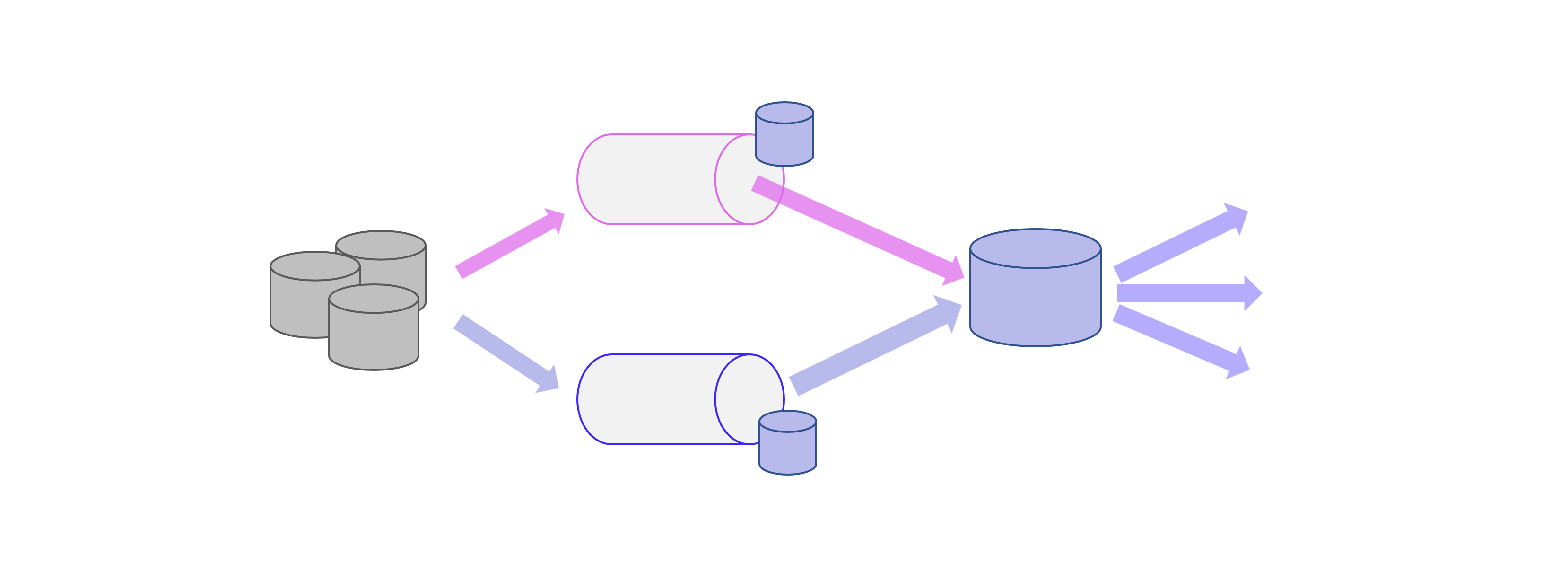
Big Data Analytics is fundamentally different from traditional data processing. Two architectural concepts are haunting the Big Data world, and companies that are just building – or reorganizing – their Big Data platform should ask themselves: Lambda or Kappa architecture?
Lambda – Architecture
The Lambda architecture was introduced in 2011, back when Big Data was still the big trending topic that filled entire conferences. While this architecture is the older of the two, it is actually the more comprehensive architecture with a batch layer, a speed layer (also known as the stream layer), and the serving layer.
The Batch Layer processes the complete data and thus allows the system to produce the most accurate results. However, the results are bought by high latency due to the batch loading as a data batch. In return, the batch layer can perform more complex calculations because there is no rush. The batch layer stores the raw data as it arrives and filters the data for the trailing applications.
Batch runs are provided for those data that are not time critical and preferably need to be loaded daily or weekly as an update (incremental load). Furthermore, batch runs become necessary if data should be completely migrated or overwritten (Full Load).
The Speed Layer produces results with low latency and almost in real time. It is used to calculate the real-time views that complement the batch views. The speed layer receives incoming data and performs incremental updates to the batch layer results. Thanks to the incremental deduction logic implemented in the speed layer, computational costs are significantly reduced.
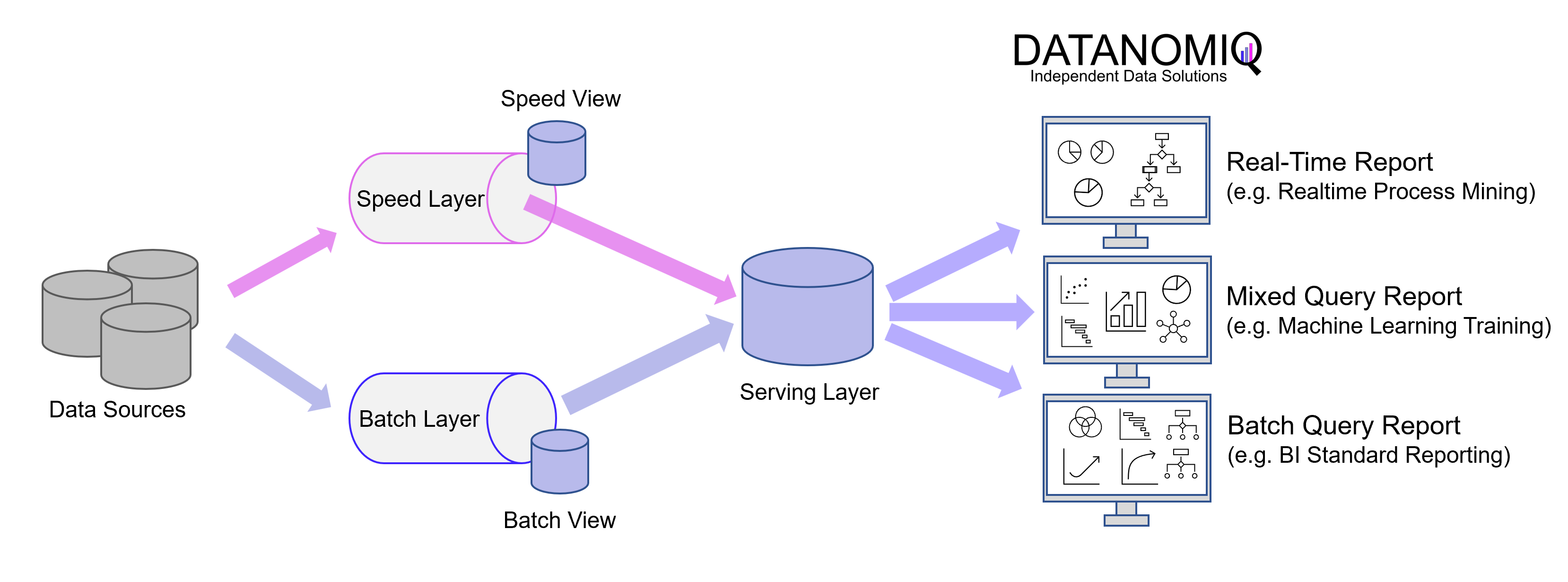
The batch views can be processed with more complex or expensive rules and therefore usually have better data quality and lower bias in the long run, while the real-time views provide up-to-date access to the most current data.
Finally, the Serving Layer enables various queries of the data sent by the batch and speed layers. The results from the batch layer in the form of batch views and the speed layer in the form of near-real-time views are passed to the serving layer, which uses this data to enable upcoming queries for standard reporting and ad hoc analytics.
The Lambda architecture can balance speed, reliability and scalability. However, although the batch layer and the real-time stream face different scenarios, their internal processing logic is often the same at the core, so development and maintenance efforts should not be underestimated.
Kappa – Architecture
The Kappa architecture was described by Jay Kreps in 2014 and removes the redundant part of the Lambda architecture by doing away with the batch part altogether. The Kappa architecture reduces architectural complexity by eliminating two pipelines running in parallel. In the Kappa architecture, only the speed layer remains in the form of an event-based streaming pipeline. The core idea is to handle real-time data processing and continuous data reprocessing with a single stream processing engine and avoid a multi-layer lambda architecture while maintaining the quality of the processing of the data.
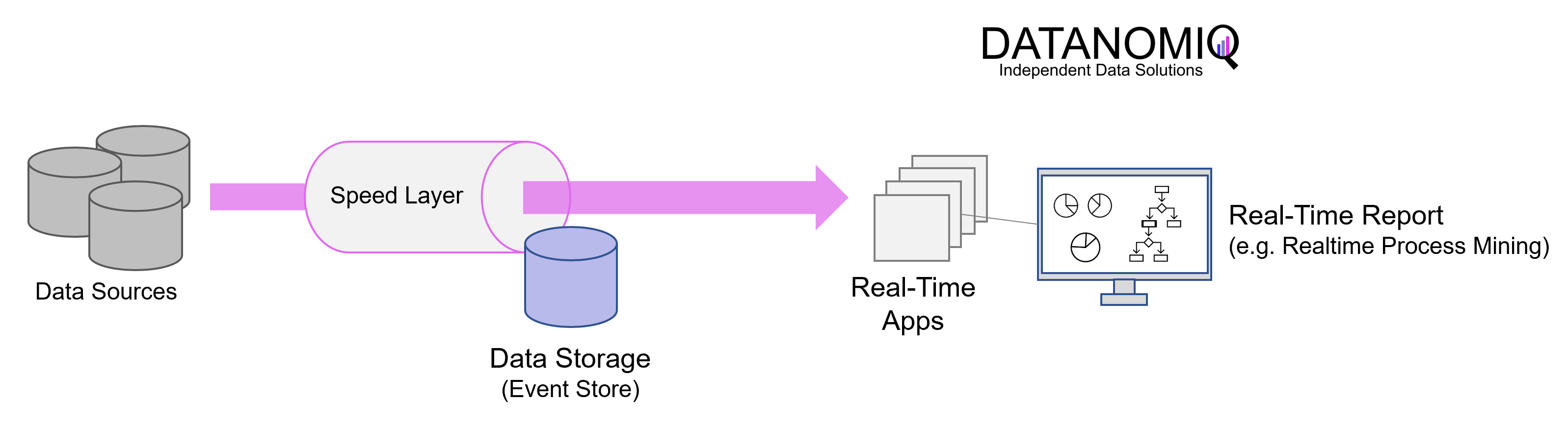
In practice, this architecture is usually implemented using Apache Kafka (or tools based on Kafka). Applications can read and write directly to Kafka (or an alternative tool in the message queue category). For existing event sources, listeners are used to stream writes directly from database logs (or equivalent data stores), eliminating the need for inbound batch processing and requiring fewer resources.
Because every data point in your organization is treated as a streaming event, you can “time travel” at any point in time and see the state of all data in your organization. Queries need only be performed at a single location, rather than having to compare batch and velocity views.
The downside of this architecture is primarily that the data must be processed in a stream and there are challenges in doing so, such as dealing with duplicate events, cross-referencing events, or maintaining the correct order of operations. Since batch processing can take more time here and consolidate multiple data sets retrospectively by itself, these challenges remain after Kappa. Architectures based on this concept are therefore more difficult to implement than those based on the Lambda concept, even though the latter may look clearer on the architecture sketch.
If the use cases for event streaming or real-time processing predominate, the Kappa architecture could make sense, since there is only this one ETL platform to develop and maintain. The Kappa architecture can be used to develop data systems that are online learning and therefore do not require a batch layer. The sequence of events and queries is not predefined and is only produced in later steps according to business logic, because the focus here is on speed.
Use cases – When to use which architecture, please?
First of all, Kappa is not a replacement for Lambda, because some use cases provided with the Lambda architecture cannot be migrated. Complex data processes and always complete data provisioning can be realized more easily with the Lambda architecture than with pure event processing according to Kappa. Most Data Lakehouse systems are therefore based on the Lambda architecture.
Requirements that clearly speak for Lambda
- If data is to be processed ad-hoc on quasi unchanging, quality-assured databases, or if the focus of the database is on data quality and the avoidance of inconsistencies.
- When fast responses are required, but the system must be able to handle different update cycles.
Requirements that clearly speak in favor of Kappa:
- When the algorithms applied to the real-time data and the historical data are identical.
- If the analytics system is online learning capable and therefore does not require a batch layer.
- The order of events and queries does not matter, but the stream processing platforms can exchange data with the database instantly at any time.
If you need an architecture that is more reliable in updating the Data Lakehouse and more efficient in training machine learning models to reliably predict events, then you should use the Lambda architecture because it takes advantage of both the batch layer and the speed layer to ensure few errors and speed.
On the other hand, if you want to deploy a leaner Big Data architecture and need effective processing of unique, continuously occurring events (e.g., to power data for many mobile applications), then choose the Kappa architecture for your real-time data processing needs.
![]() DATANOMIQ is the independent consulting and service partner for business intelligence, process mining and data science. We are opening up the diverse possibilities offered by big data and artificial intelligence in all areas of the value chain. We rely on the best minds and the most comprehensive method and technology portfolio for the use of data for business optimization.
DATANOMIQ is the independent consulting and service partner for business intelligence, process mining and data science. We are opening up the diverse possibilities offered by big data and artificial intelligence in all areas of the value chain. We rely on the best minds and the most comprehensive method and technology portfolio for the use of data for business optimization.